19 Aug 2014
In my day job we use the excellent Librato Metrics
service to push all our metrics data to for monitoring and visualisation. We've
been primarily using StatsD to collect metrics from our various applications,
and the AWS integration for data on
those services. Something we've been missing though is some server level
information that isn't provided with Cloudwatch (specifically
disk space and memory). I've been meaning to try using collectd
to collect this and then push it off to Librato somehow. Then luckily the Librato team announced
native integration...
Just what we needed!
Ansible Configuration
Luckily Collectd was available through the package manager on our current
distribution, so I set right to creating an Ansible role for it...
# roles/collectd/tasks/main.yml
---
- name: Package Installed
yum: pkg=collectd state=present
tags:
- collectd
- name: Configured
template: src=collectd.conf.j2 dest=/etc/collectd.conf
owner=root group=root mode=644
tags:
- collectd
notify:
- restart collectd
- name: Service Running
service: name=collectd state=started enabled=true
tags:
- collectd
With the associated handler...
# roles/collectd/handlers/main.yml
---
- name: restart collectd
service: name=collectd state=restarted
And basic configuration file for testing the setup on my VM...
# roles/collectd/templates/collectd.conf.j2
Hostname "{{ inventory_hostname_short }}"
FQDNLookup false
LoadPlugin load
LoadPlugin memory
LoadPlugin df
LoadPlugin write_http
<Plugin write_http>
<URL "https://collectd.librato.com/v1/measurements">
User "{{ librato_email }}"
Password "{{ librato_token }}"
Format "JSON"
</URL>
</Plugin>
Include "/etc/collectd.d"
Helpfully the configuration is provided when you enable the service integration
in Librato as well:
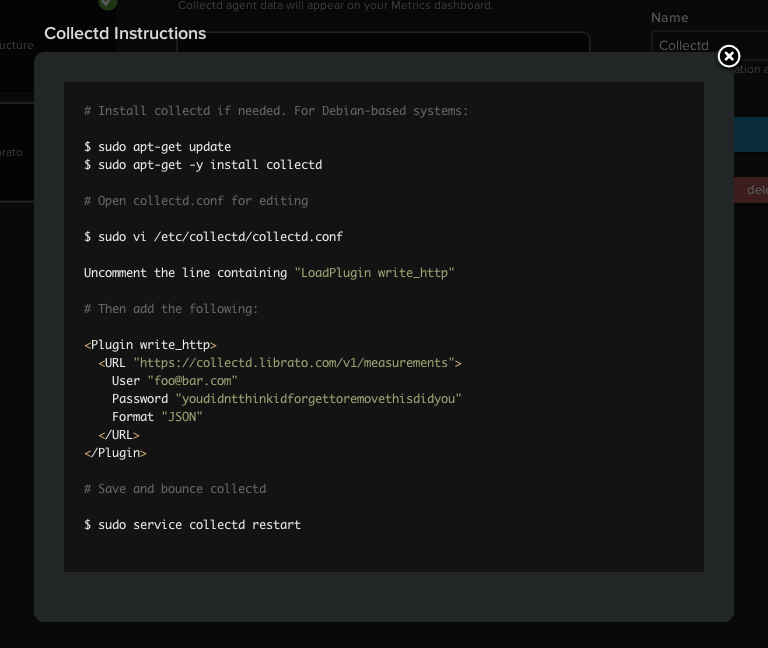
Just Works?
After adding the role I quickly reprovisioned my development VM and switched to
Librato to watch the data roll in... and it did! Some quick testing,
deployment to our test environment for final checking and then it was
straight out to production - thanks Librato!
The collectd plugins are easily configured now through my Ansible scripts, time
to dive in to the data! :)
21 Jul 2014
While making what I thought was going to be a two second change to a MySQL
query today I found myself waiting a full 60 seconds for the results when I
first ran it. Not a good start, let's have a look at an example with all the
cruft removed (background: there are applications, each having many quotes)
1 select
2 a.id,
3 a.name,
4 a.etc,
5 quotes.total -- find quote total for applications
6 from applications a
7 left join (
8 select application_id, count(*) as total
9 from quotes
10 group by application_id
11 ) quotes
12 on quotes.application_id = a.id
Now the reduced query above looks pretty contrived, but it's only because I've
removed all the other joins and selects. In the above example the query could
be written much more concisely (to essentially be the derived table) - but in
my real query there are many more joins which mean that aggregating on the
quotes join is not possible.
Full Table Scan Time
Here's a snippet of the explain output - with the index information removed as
it was too wide for the page, but it's not important...
| select_type |
table |
type |
... |
ref |
rows |
Extra |
| DERIVED |
quotes |
index |
... |
NULL |
451839 |
Using index |
If you're not familiar with MySQLs EXPLAIN keyword, the important part to
note is the rather large number of rows that are being scanned to create the
result set. Bugger...
Using derived tables to compute aggregates this way is a technique I've used
quite a bit and never really had a problem with. Usually it's a simple way to
pull in more information to your query without complicating the JOIN situation.
Adding indexes didn't seem to help, at least I couldn't work out any that were
missing that I could add. The derived table was correct, and if executed alone
it would indeed scan the entire quotes table as it needs to.
Derived to subquery
What I imagined would be happening here is that the query plan would be
generated to evaluate outside-in, so selecting all matching applications and
then creating the derived table to calculate quote totals for each. This
doesn't appear to be the case however, as a much larger portion of the quotes
table is actually being scanned - though far from all of it.
What I tried (randomly) was to move the derived table to be a subquery in the
SELECT portion of the query (hoping for the result I assumed above).
1 select
2 a.id,
3 ( select count(*)
4 from quotes
5 where quotes.application_id = a.id ) as total
6 from applications a
7 -- etc...
Here's the new EXPLAIN snippet...
| select_type |
table |
type |
... |
ref |
rows |
Extra |
| DEPENDENT SUBQUERY |
quotes |
ref |
... |
database.a.id |
1 |
Using where |
Much better! And more importantly execution time is down from 60 seconds to
about 65 milliseconds.
Lesson Learned
There was no particular reason I was using derived tables over this method
previously, it's just a technique I knew that gave me the results I needed. But
I'm glad I've got another tool to work with when I approach these same
situations in the future.
Of course, if there's something I've missed or a better way to approach this
please let me know!
05 Jul 2014
Yesterday I spent about half an hour tracking down a bug that had cropped up mid feature development. Everything was working fine... then for some reason two of my vars appeared to have the same value, when they really shouldn't have. After much "GGrraaah!!" and many "Waaaatt?'s I found the problem...
<?php
protected function foo(
DateTime $fromTime,
DateTime $toTime,
DateTime $fromTime,
DateTime $toTime
) { ...
Now reading that it's probably obvious something is not right, but this was the result of either some spurious renaming or copy pasting, I didn't catch it right away. But then I thought about it, shouldn't the compiler be catching this kind of error? PHP is a dynamically typed language, but you'll still get errors about duplicate method/property names, why not parameter names? I cried out to the Twitter...

I guess it's kind of expected, but the fact that it had caused a bug (which I luckily caught before it got any further) was clearly a problem.
This morning fellow elite hacker Ian "Jonko" Jenkins mentioned that he'd tried this in a few other languages and got some of the same result. So how do other languages fair? Let's see, first everyones favourite Javascript...
function foo(x, x) {
return x;
}
foo(1, 2); // 2
The result is 2, the same as PHP. Javascript is dynamically typed as well, interesting... How about Python...
def foo(x, x):
x
print foo(1, 2)
This time an error!
SyntaxError: duplicate argument 'x' in function definition
Hoorah for Python. Ruby next...
def foo(x, x)
return x
end
puts foo(1, 2)
And another error!
Now a personal favourite Clojure, come on do me proud...
(defn foo [x x] x)
(foo 1 2)
Gah, failure, it happily returns 2... Let's try Java...
package rod;
class Test {
public function foo(int x, int x) {
return x;
}
}
And as I suspected it caught the problem, which a lot more information that the other languages that did.
variable x is already defined in method foo public function foo(int x, int x) {
So given the fact that Python and Ruby passed the "test" quite happily there can't be anything intrinsic about dynamic languages that make this kind of checking impossible to do. Perhaps it's just an afterthought, I mean who in actual reality is going to do this... I guess.
Have any deep insights about why this "functionality" might exist, want to post how your favourite language fairs, just use the comments below. Back to hacking.
01 Jun 2014
I've always wondered this... just why does clearing the cache with Symfony2 take so long, and use so much memory?
The answer is I still don't really know, but welcome to my adventure on speeding up deployments and reducing memory usage.
I've been told that Symfony loads the application into memory (as it would do running any other task) before clearing the cache folder. Recently I've been running into problems with this actually running out of memory during deployments to my production environments, so switched it to the more brute force...
But wondered if this had any side-effects...
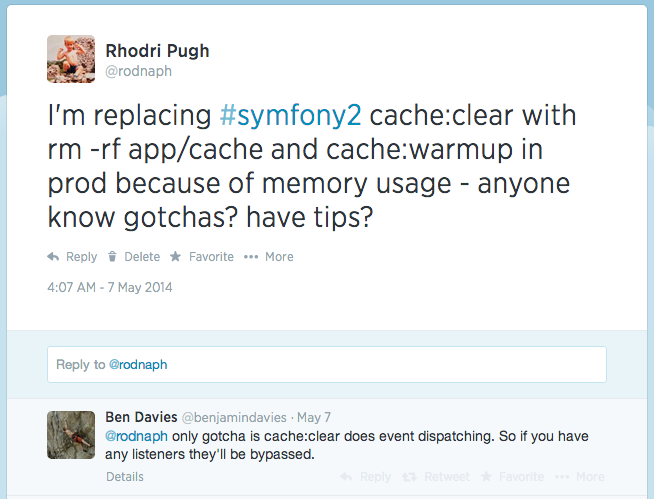
Afaik I'm not using any cache event listeners, and testing it seemed all good. As I mentioned in the tweet I also need to now call cache:warmup (which is called by default on cache:clear unless you specify --no-warmup).
Rolling out to production things were better. Clearing the cache during a deployment was now a much quicker process, but I was still occasionally running into out of memory errors on the cache:warmup.
Warming up the cache for the prod environment with debug false
ERROR 9
So next I looked into the warmup command... What I learned was that there are required and optional cache warmers. The later can be disabled by using the flag --no-optional-warmers. I've found that this significantly speeds up cache warming, and crucially means that I don't suffer from out of memory failures.
Of course, the warming of these caches is only deferred until runtime, so if this would be a problem for you then it might not be an option. But in my case it's something I can deal with.
12 May 2014
I've been using Jenkins since it was Hudson, and in a bunch of different configurations. My first experience was when working with a large client who had a big deployment that automated their entire build cycle through multiple stages. Seeing how awesome this (free!) tool was the company I worked for proceeded to give it a spin, and I think it probably started out running on one of the developers machines for more than a while. Over the next few years it grew to be managed by developers, then by ops, then kind of by everyone... oh, in single-server and master/slave setups.
The constants I've seen through all this change though seem to be the following...
- Be it because of plugins or cosmic rays, given a long enough period of time... all Jenkins instances will break. It's like ultimate Jenga.

- Jobs don't always pass, and when this happens often the only way to debug things is on the CI server itself.
- Contention arises through the performance of this shared resource.
Trying to prevent these issues usually has the consequence that arguments about access and ownership arise. Who's responsibility is it to fix it, who should be ensuring it's capacity, and who is allowed to access it? It's because of this that in my current role I'm trying a new way of using Jenkins, by decentralising it to each developer.
Even modest development machines these days probably pack a fair bit of punch, and I'd guess that most of the time that power isn't being used (When we're typing the computer doesn't have to do that much, right? Well, Eclipse aside of course...). So using a VM (or Docker image) for Jenkins shouldn't be too much of a problem, you probably have one for your development environment already.
I've become a big fan of Ansible over the last 6 months, and have fully configured my Jenkins VM with all the jobs that are needed. This has the following benefits...
New developers can spin up an instance in no time at all.
No need to bother with Jenkins roles and permissions.
Should I balls up my instance, I can easily create a new one.
If I suspect anything funky going on with my jobs, I've full access to investigate (without risking introducing problems for others)
I am free to innovate and experiment with new stuff on my instance (again, without the risk of affecting anyone else)
Knowledge about the system will hopefully be spread more evenly around all the users because of the no-hassle access, and complete ownership.
Decentralisation reduces the risk of Jenkins becoming a single point of failure when shit hits the fan at the wrong time.
I'm currently working in a very small team of two, so can't claim I've rolled this out to an organisation and it's brilliant - but it's working nicely enough so far so I just wanted to share my thoughts.
Of course, this wouldn't work for everyone (if you need it to be a high-performance dedicated machine, maybe for long running batch jobs for instance) but I think it could cover a lot of cases. Access to shared resources like package repositories can be configured and provisioned automatically, leaving less (hidden) magic knowledge that suddenly becomes lost.
Tried this yourself? Have a better system? Think I'm an idiot? Let me know :)